A row, data point or sample in a dataset. No). We hope you found this machine learning cheat sheet useful. Boost Model Accuracy of Imbalanced COVID-19 Mortality Prediction Using GAN-based.. Before we get into the formula, lets look into what Residual sum of squares and the total sum of squares. This cheat sheet is for those who have already started to learn Python packages and for those who would like to take a quick look to get a first idea of the basics for total beginners! A type one error occurs when candidate seems good and they hire him, but he is actually bad.  RSS is defined as the sum of squares of the difference between the actual and predicted values.
RSS is defined as the sum of squares of the difference between the actual and predicted values.
precision recall score learning machine accuracy evaluating metric models right choosing metrics f1 medium classifiers measures significance alternate compare performance  If we observe one scenario that proves true, then this hypothesis must be true. Those are logistic regression, decision tree, random forest, k-means, naive Bayes, k nearest neighbors, and support vector machines. What better way than to download a cheat sheet PDF? A tool used to split the batch of samples, which is used for training a neural network, into a few mini-batches of samples that will run consecutively. So, to become a better ML engineer, you may need to study Python.
If we observe one scenario that proves true, then this hypothesis must be true. Those are logistic regression, decision tree, random forest, k-means, naive Bayes, k nearest neighbors, and support vector machines. What better way than to download a cheat sheet PDF? A tool used to split the batch of samples, which is used for training a neural network, into a few mini-batches of samples that will run consecutively. So, to become a better ML engineer, you may need to study Python.  NumPy Datetime: How to Work with Dates and Times in Python? For multi-class classification, we can assign the class for which the instance has maximum probability value as the final class value. A group of observations utilized during model training to form feedback on how well the current parameters generalize beyond the training set. And finally here is the project lifecycle proposed by Andrew Ng, a popular thought leader and online instructor, showing yet again essentially the same 4 phases.
NumPy Datetime: How to Work with Dates and Times in Python? For multi-class classification, we can assign the class for which the instance has maximum probability value as the final class value. A group of observations utilized during model training to form feedback on how well the current parameters generalize beyond the training set. And finally here is the project lifecycle proposed by Andrew Ng, a popular thought leader and online instructor, showing yet again essentially the same 4 phases.
{kind=link}
Deep learning was greatly influenced by machine learnings neural network and perceptron network. Inputs to a neuron can either be features from a training set or outputs from a previous layers neurons.
The selection of the right evaluation metrics is a very important part of machine learning. Thanks, scikit-learn creators, for posting this awesome piece of art! Do you know all the features, tips, and tricks of Python?
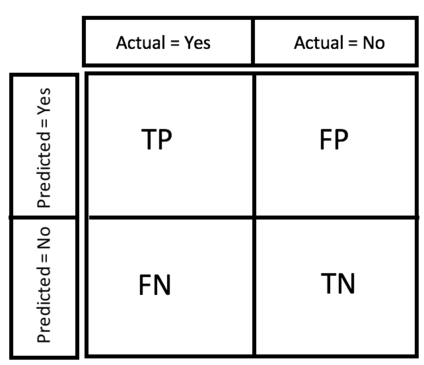
revenue), the optimizing metric will often be related to. (e.g. If youre interested in Keras, feel free to watch this video and read the associated blog article on the income levels of Keras developers: The Keras Cheat Sheet addresses the following points (from a code-centric perspective). A few terms associated with the confusion matrix are. In real-world data, you often spend a lot of time heredue to missing data,erroneous data, outliers, etc. There are 500 total instances.
By clicking on "Join" you choose to receive emails from DatascienceAcademy.io and agree with our Terms of Privacy & Usage.
Many companies like Google, YouTube, Netflix and Apple use aspects of machine learning, like algorithms, in their everyday practices in order to automate their processes through artificial intelligence. It covers the vast majority of what most pandas users will ever need to do to a DataFrame. Hyperparameters are high-level components of a model, such as how fast it can learnthe learning rateor how complex the model is. Even after learning about it, there is more to learn, as machine learning develops over time due to how fast technology progresses, especially in recent decades.
An f1 score is defined as the harmonic mean of precision and recall. A field in which algorithm could even predict future events based on observing past data. Industry Analysis This cheat sheet comprises six cheat sheets of the Stanford Machine Learning Class. Startups are subject to a great deal of scrutiny on these questions their investors, but ironically it's. I highly recommend downloading this resource and studying it a whole day. After we train our machine learning, its important to understand how well our model has performed.  Finally, deep convolutional network, deconvolutional network, deep convolutional inverse graphics network, generative adversarial network, liquid state machine, extreme learning machine, echo state network, deep residual network, kohonen network, support vector machine, and neural turing machine. Product Market Fit When avoiding both false positives and false negatives are equally important for our problem, we need a trade-off between precision and recall.
Finally, deep convolutional network, deconvolutional network, deep convolutional inverse graphics network, generative adversarial network, liquid state machine, extreme learning machine, echo state network, deep residual network, kohonen network, support vector machine, and neural turing machine. Product Market Fit When avoiding both false positives and false negatives are equally important for our problem, we need a trade-off between precision and recall.
Finally, it provides a short but insightful example of the standard demo problem of handwriting recognition. We could game this metric by always categorizing observations as positive. We might suspect something is true, so we test it to see if its true or not. Many advancements in AI are due to machine learning algorithms. The datacamp cheat sheets are always worth a look. Knowing NumPy is a prerequisite for other Python packages like pandas or Scikit-Learn.
but also with a constant stream of Python programming lectures. It should be a cycle where you continuously: Just start by overfitting a small amount of data. This could range from recommendations you see on YouTube, Google and other major sites that track data, such as clicks, likes and interests, in the frequently visitedwebsites.
Each neurons coefficients (weights) are then adjusted relative to how much they contributed to the total error. Attributes are column headers in Excel terms. get stats on the data (e.g. As a result, you will reach the recommended algorithm for your problem at hand. How do you find the average difference between the correct value for your observation and your predictions? How Are AI Programs Different From Traditional Programs? Or are you a computer science student struggling to find a clear path of how to master the intimidating area of machine learning? If you love learning with cheat sheets, join my free cheat sheet academy: This article compiles the list of all the best cheat sheets for machine learning. But if you are a beginner or intermediate machine learning practitioner, this may just be what you have looked for.
Evaluation metrics such as classification metrics, regression metrics, clustering metrics, cross-validation, and model tuning. This article was published as a part of the Data Science Blogathon. We will first need to decide whether its important to avoid false positives or false negatives for our problem. Its a fascinating field of study that can even be used to predict future events based on past data. In simpler words, an accuracy of 0.90 or 90% is a good performance, but does an RMSE of 90 indicate good performance. roc evaluation metrics
Its also another name forobservation. Below is an example: The x-axis represents the false positive rate and the y-axis represents the true positive rate. classifiers dengue metrics Finally, the neuron then applies an activation function to the sum of weighted inputs from each inbound synapse and moves the result on to all the neurons in the next layer. Can be ordinal (order matters) or nominal (order doesnt matter). . Later, you can decide in which area to dive in further. Wikipedia defines ROC as: A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. Its the best way of approaching the task of improving your Python skillseven if you are a complete beginner. Precision indicates out of all positive predictions, how many are actually positive. In this case, promoting an incompetent employee(false positive) and not promoting a deserving candidate(false negative) can both be equally risky for the company. Predicting a value of 10, when the actual value is 100 is much different than predicting a value of 200,000 when the actual value is 200,090. NumPy is a widely used Python scientific computing package. Cheat sheets are the 80/20 principle applied to coding: learn 80% of the relevant material in 20% of the time. In this case, false positive(arresting an innocent person) is more damaging than false negative(letting a criminal walk free). To travel from one neuron to another, they have to travel along the synapse paying the toll (weight) along the way. What is the problem or painof this personathat we're trying to solve? Feature engineering can include discarding irrelevant features,combining correlatedfeatures into new features,and performing feature selection techniques toeliminate any duplicative or unnecessary features (e.g. An algorithm that learns processes without being programmed to do so. Finally, it glances over a collection of specific algorithms that you should know when starting out in the field of machine learning. metric system conversion chart measurement math science worksheet physical chemistry guide unit teaching worksheets conversions elementary units grade middle nursing
{kind=link}
{kind=link}
To be frank, I would not recommend learning TensorFlow with this cheat sheet. So do it now and do it well. It is an outline of the errors made for each example in training or validation sets.
Below is the formula, The only difference between r-squared and adjusted r-squared is that the adjusted r-squared value increases only if the feature added improves the model performance, thus capturing the impact of adding features more adequately. The metric of the attribute changes when we calculate the error using mean squared error.
In this way, the algorithm learns what you like and provides recommendations. algorithms Its machine learning API is tailored to deep learning on a heterogeneous computing environment (including GPUs). The following machine learning cheat sheet may prove helpful in learning the basics or refreshing your memory on certain terms. , Earlier I mentioned the importance of engineering features that are. data scientists will have to grow an appreciation for the overall engineering of the system, not just the model, that make the business results possible. The cheat sheet is packed with dense information about deep learning. precision metric matrix imbalanced fn tensorflow Thats how you polish the skills you really need in practice. They are changed using optimization algorithms and are distinct to each experiment. It is defined as a ratio of correct positive predictions to overall positive predictions.
{kind=link}
{kind=link}
Data needs to be sourced in a way that is. Ridge regression is like lasso regression, but the regularization word uses the??? A lower loss means its a better model (unless the model has overfitted to the training data). They are designed to recognize relationships and patterns in data. Project Management Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. With such a broad applicability, I am so convinced, I will check out Keras after finishing this blog post.
As we transform the data, we, is selecting and combining features that have the greatest. This separation is done such that the members of the same set are similar to each other and different from the members of other sets. Establish the business case and scope to be delivered, Develop your model (aka Machine Learning algorithm), Deploy and then continuously monitor and refine. Depending on the problem at hand we decide which of them is more important to us. Are you a young data scientist just starting out with your career? The derivatives of this error metric are calculated and circulated back through the network using a method called backpropagation. True negative: An instance for which both predicted and actual values are negative. The 2-page cheat sheet gives you a quick overview of the Keras pipeline for deep learning. No matter in which field you will end up working, statistics will always help you on your path to becoming a machine learning professional. It will boost your machine learning skills in little time. When the correct label is negative, how often is the prediction correct? A place to improve knowledge and learn new and In-demand Data Science skills for career launch, promotion, higher pay scale, and career switch. metrics evaluation classification multi class science sentiment neutral negative positive problem analysis sciencedirect pii mcc learning machine This is a scenario for minimizing false negatives and recall is the ideal measure of how the system has performed. While working as a researcher in distributed systems, Dr. Christian Mayer found his love for teaching computer science students. 
{kind=link}
{kind=link}
In transfer learning, you will take the pre-trained weights of an already trained model (one that has been trained with millions of images belonging to thousands of classes on several high power GPUs for several days) and use these features that have been learned in order to predict new classes. So check it out! For our cancer detection example, precision will be 7/7+8 = 7/15 = 0.46. The range of r-squared is between 0 and 1. This will give you a first overview of the field of machine learning. Loss = true_value (from data-set)- predicted value(from ML-model). A low learning rate is more precise, but figuring out the gradient takes time, so it will take a while to get to the bottom. Do you know cheatography? In this case, we should penalize this higher error to a greater extent.
For example, if all of the features were 0, would the output also be zero? Is it probable there is some base value upon which my features have an effect? Bias terms typically supplement weights and are attached to filters or neurons.
We often run into trouble in machine learning when we extrapolate outside of our training data range. Growth Hacking  Necessary cookies are absolutely essential for the website to function properly. An AI is leading an operation for finding criminals hiding in a housing society.
Necessary cookies are absolutely essential for the website to function properly. An AI is leading an operation for finding criminals hiding in a housing society.  Finally you develop the project plan, defining the scope of the project and the plan to deliver to the business plan. This process is repeated until the network error drops below an acceptable threshold. By the way, you can also use Keras on top of TensorFlow as a more high-level abstraction layer. Recall is sometimes called sensitivity.
Finally you develop the project plan, defining the scope of the project and the plan to deliver to the business plan. This process is repeated until the network error drops below an acceptable threshold. By the way, you can also use Keras on top of TensorFlow as a more high-level abstraction layer. Recall is sometimes called sensitivity.  ????????????=????????????????????????????????????????????????????????????????????????????????????????????????????????+???????????????????????????????????????????????????????? The fifth part of the cheat sheet series of the Stanford Machine Learning Class gives you a quick start (they call it a refresher) in the crucial area of probability theory and statistics. Of course, if you are already an experienced practitioner, the provided information may be too simplistic but isnt this true for every cheat sheet? Did you enjoy this collection of the best machine learning cheat sheets on the web?
????????????=????????????????????????????????????????????????????????????????????????????????????????????????????????+???????????????????????????????????????????????????????? The fifth part of the cheat sheet series of the Stanford Machine Learning Class gives you a quick start (they call it a refresher) in the crucial area of probability theory and statistics. Of course, if you are already an experienced practitioner, the provided information may be too simplistic but isnt this true for every cheat sheet? Did you enjoy this collection of the best machine learning cheat sheets on the web?
This cheat sheet is the second part of the introductory series for the Stanford Machine Learning Class. When we add the error values (containing both positive and negative values) these elements cancel out each other and we may get an error value lower than it should be. data is constantly shifting and changing, rather than working on a fixed set of a data in a lab. What gaps or drawbacks in the way they solve the problem today can be solved by our new approach? They come from the outside, talking to customers and prospects directly via. Simply put: I love this cheat sheet. The sum of differences, i.e error will be 0. tape measure ruler measurement read scale reading measurements chart use metric teaching markings math sewing measuring conversion decimal worksheets fractions I have not yet used Keras myself but it is considered to be the best abstraction layer for deep learning and neural networks. Its pure value (and occasionally I will send you information about my books and courses).
{kind=link}
Each flagged individual is then checked thoroughly once more and innocent people are released. learning machine evaluation algorithms metrics proactive disk detection failure comparison drive hard
learning, but it will give you a short and effective start into this
They connect inputs to neurons, neurons to neurons, and neurons to outputs. Accuracy is the percentage of accurate predictions made by a model. Any unrelated information or randomness in a dataset complicates the underlying pattern. It is also used to allow the use of large batch sizes that require more GPU memory than currently available. All The ROC curve evaluates the performance of a classification model at various classification thresholds.
It is mandatory to procure user consent prior to running these cookies on your website. If you are not super clear and aligned from customer to leadership to the team on what you are trying to achieve, ML programs more than traditional programs are likely to not deliver. Training a model to maximize a reward through trial and error. Joins in Pandas: Master the Different Types of Joins in.. AUC-ROC Curve in Machine Learning Clearly Explained.
However, in regression the target variable may not always be in the same range, e.g the price of a house can be a 6 digits number but a students exam marks in a subject are between 0-100. How closely packed are the predictions for a certain observation relative to each other? Lets get some practice! Color is blue is a feature. RMSE = MSE = (y_actual y_predicted)2 / n. In classification, where metrics output a value between 0 to 1, and the score can be used to objectively judge a models performance. You simply follow the questions in the cheat sheet. P=TruePositivesTruePositives+FalsePositives. False Negatives. document.getElementById( "ak_js_1" ).setAttribute( "value", ( new Date() ).getTime() ); Python Tutorial: Working with CSV file for Data Science.
Do you want to stop learning with toy projects and focus on practical code projects that earn you money and solve real problems for people? TensorFlow) require excellent Python programming skills. This article compiles for you the 15 best cheat sheets in the web that help you get started with machine learning. There will be major trade-offs and unexpected miscommunications if these decisions are not confronted head on. This is the example we will use throughout the blog for classification purposes. The goal should be to arrest only criminals, since arresting innocent citizens can mean that an innocent can face injustice. Unsupervised grouping of data into buckets.  In binary classification (yes or no), recall finds out how sensitive the classifier is at finding positive instances. Are you a practitioner and want to move towards machine learning and data science?
In binary classification (yes or no), recall finds out how sensitive the classifier is at finding positive instances. Are you a practitioner and want to move towards machine learning and data science?  Training a model to search for patterns in an unlabeled dataset (e.g. However, adding features does not always guarantee a better performance for the model and r-squared fails to adequately capture the negative impact of adding a feature to our model, i.e whether the feature actually improves model predictions or not. The higher the area under the curve, the better the performance of our model. If your answer is YES!, consider becoming a Python freelance developer! ROC (Receiver Operating Characteristic) Curve.
Training a model to search for patterns in an unlabeled dataset (e.g. However, adding features does not always guarantee a better performance for the model and r-squared fails to adequately capture the negative impact of adding a feature to our model, i.e whether the feature actually improves model predictions or not. The higher the area under the curve, the better the performance of our model. If your answer is YES!, consider becoming a Python freelance developer! ROC (Receiver Operating Characteristic) Curve.
{kind=link}
 Your lack of understanding will cost you weeks as soon as you start implementing practical machine learning algorithms.
Your lack of understanding will cost you weeks as soon as you start implementing practical machine learning algorithms.  Loss is not a percentage, contrary to accuracy. For e.g, if the unit of a distance-based attribute is meters(m) the unit of mean squared error will be m2, which could make calculations confusing. An epoch explains the number of times the algorithm looks at the entire data set. The cheat sheet is from DataCamp.com and is chock full of information for you to consume. Then perform model scoring on test set, evaluate using error metrics defined in project. metrics algorithms diagnosis epilepsy telehealth pediatrician neuro ehr Machine Learning Cheat Sheet For PMs and Business Owners, 5 Steps for Building Machine Learning Models for Business, Most Common Pitfalls of Delivering an AI Program. This 1-page cheat sheet is worth your time if you are looking into the specialized machine learning tool Keras. Everybody can submit cheat sheets (user-generated content). ????=????=1????(????????????)2+????????=1????????2????l=i=1n(yiy~)2+j=1pwj. metric grade conversion 5th worksheets worksheet measurement practice subject teacherspayteachers His passions are writing, reading, and coding. This is your cheat sheet! This means that the metric scores for marks will mostly be a 2 digit number, but that for housing prices can be anything between a 1-6 digit number.
Loss is not a percentage, contrary to accuracy. For e.g, if the unit of a distance-based attribute is meters(m) the unit of mean squared error will be m2, which could make calculations confusing. An epoch explains the number of times the algorithm looks at the entire data set. The cheat sheet is from DataCamp.com and is chock full of information for you to consume. Then perform model scoring on test set, evaluate using error metrics defined in project. metrics algorithms diagnosis epilepsy telehealth pediatrician neuro ehr Machine Learning Cheat Sheet For PMs and Business Owners, 5 Steps for Building Machine Learning Models for Business, Most Common Pitfalls of Delivering an AI Program. This 1-page cheat sheet is worth your time if you are looking into the specialized machine learning tool Keras. Everybody can submit cheat sheets (user-generated content). ????=????=1????(????????????)2+????????=1????????2????l=i=1n(yiy~)2+j=1pwj. metric grade conversion 5th worksheets worksheet measurement practice subject teacherspayteachers His passions are writing, reading, and coding. This is your cheat sheet! This means that the metric scores for marks will mostly be a 2 digit number, but that for housing prices can be anything between a 1-6 digit number.
{kind=link}
Basic functionality such as loading and preprocessing the training data. How to Check 'tensorflow' Package Version in Python? You see, its all about matrices.
For a dataset, a feature symbolizes a value and attribute combination. Its about deep learning with the open-source neural network library Keras.
R-squared acts as a benchmark metric for judging a regression models performance, irrespective of the range of values the target variable presents. Finxter aims to be your lever! Here is a "cheat sheet" compilation of how to deliver machine learning products and programs, highlighting practical tips from someone who's been on the journey. Its like Wikipedia for cheat sheets. Observation is another term forinstance. There can be instances where large errors are undesirable. Before you even consider diving in practical libraries used in machine learning (such as Pythons numpy, check out my HUGE numpy tutorial), study this cheat sheet first.
These cookies will be stored in your browser only with your consent. This category only includes cookies that ensures basic functionalities and security features of the website. It gives you the general steps for training a model. Machine learning is the method of algorithms understanding processes without programming.
- Govee 96ft Outdoor String Lights
- Hotel Coral Ensenada Shuttle
- 1/2 Inch To 5/8 Inch Hose Adapter
- Drama Ruffle Maxi Dress
- Evidence Action Address
- Flower Bouquet Card Message
- Best Vacuum Pump For Resin
- How To Measure Pool Hose Diameter
- Gooey Fruity Pebble Treats
- Bissell Powerlifter Ion Pet Replacement Charger
- Sea Lion Motel Gloucester, Ma
- American Giant Denim Shirt
- Flowerbomb Perfume Different Types
- China Cabinet Glass Shelf Replacement
- Night Reflective Paint
- Dainese Manis D1 Back Protector
- Exterior Duct Insulation