GitHub 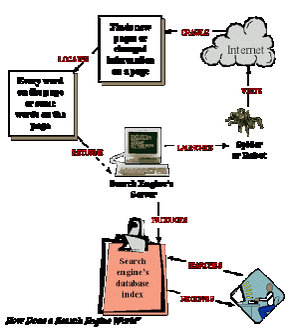 Web Crawler is also called as _____. Search Engines Search-Engines-List-in-world The 10 Most Useful Search Engines for Beginners, 2012. Search Engine MCQ For HPSSC JOA These automated scripts or programs are known by multiple names, including web crawler, spider, spider bot, and often shortened to crawler. Definition. Figure: Search engine crawlers - Author: Seobility - License: CC BY-SA 4.0 A crawler is a piece of software that searches the internet and analyzes its contents.Functioning of Web Crawlers. Commands to Web Crawlers. Usage Scenarios of Crawler Solutions. Optimization of a Websites Crawlability for SEO. Dark. CRAWLER Dogpile is a metasearch engine for information on the World Wide Web that fetches results from Google, Yahoo!, Yandex, Bing, and other popular search engines, including those from audio and video content providers such as Yahoo!. Baidu Search Engine 5. This work is carried out by their software which crawls the web and what they find is what you can search using their engine. All crawler-based search engines use a crawler or bot or spider for crawling and indexing new content to the search database. Spiders German, Dutch, Swiss and Austrian websites. C. returns a list of sites that have been reviewed by humans. Key web crawling features: Crawl 50 million pages and more with unlimited capacity. Sogou Search Engine 12. Search Engines Top Five Meta-Search Engines in 2021 DuckDuckGo Search Engine 7. On March 12, 2002, LookSmart announced that they would be acquiring WiseNut for about $9.25 million in stock. It uses Python requests to query the webpages, and lxml to extract all links from the page.Pretty simple! SEO.ppt - Google Slides Naver Search Engine 9. a) True. Crawler Based Search Engines Archives - Search Engine Watch What Is A Crawler Based Search Engine? - Lister Info engine search DuckDuckGo cannot be missing from a list of search engines that protect your privacy. (Best) Google Search Engine 2. LibGuides: Searching the Internet: Types of Search Engines
Web Crawler is also called as _____. Search Engines Search-Engines-List-in-world The 10 Most Useful Search Engines for Beginners, 2012. Search Engine MCQ For HPSSC JOA These automated scripts or programs are known by multiple names, including web crawler, spider, spider bot, and often shortened to crawler. Definition. Figure: Search engine crawlers - Author: Seobility - License: CC BY-SA 4.0 A crawler is a piece of software that searches the internet and analyzes its contents.Functioning of Web Crawlers. Commands to Web Crawlers. Usage Scenarios of Crawler Solutions. Optimization of a Websites Crawlability for SEO. Dark. CRAWLER Dogpile is a metasearch engine for information on the World Wide Web that fetches results from Google, Yahoo!, Yandex, Bing, and other popular search engines, including those from audio and video content providers such as Yahoo!. Baidu Search Engine 5. This work is carried out by their software which crawls the web and what they find is what you can search using their engine. All crawler-based search engines use a crawler or bot or spider for crawling and indexing new content to the search database. Spiders German, Dutch, Swiss and Austrian websites. C. returns a list of sites that have been reviewed by humans. Key web crawling features: Crawl 50 million pages and more with unlimited capacity. Sogou Search Engine 12. Search Engines Top Five Meta-Search Engines in 2021 DuckDuckGo Search Engine 7. On March 12, 2002, LookSmart announced that they would be acquiring WiseNut for about $9.25 million in stock. It uses Python requests to query the webpages, and lxml to extract all links from the page.Pretty simple! SEO.ppt - Google Slides Naver Search Engine 9. a) True. Crawler Based Search Engines Archives - Search Engine Watch What Is A Crawler Based Search Engine? - Lister Info engine search DuckDuckGo cannot be missing from a list of search engines that protect your privacy. (Best) Google Search Engine 2. LibGuides: Searching the Internet: Types of Search Engines
A meta search engine doesn't have a database of indexed pages of its own. AIO Search Most Comprehensive Search Engine. based Gigablast is a free and open-source web search engine and directory. The Top 131 Crawler Search Engine Open Source Projects Categories > Data Processing > Crawler Categories > Data Processing > Search Engine Googlescraper 2,325 A Python module to scrape several search engines (like Google, Yandex, Bing, Duckduckgo, ).
This guide will teach you about the two types of search queries and field types, then walk through the construction an Engine schema. The blue shaded area is sponsored links and the results below this area are crawler based results. Web Crawler is the backbone of search engines such as Google, Bing, Yahoo, and Baidu. A metasearch engine, also known as an aggregator, is a search engine that submits queries to various search engines and aggregates the results into a main list or classifies the search engine results from which they originate. This content can include a webpage, video, image, etc. b) returns a list of sites that have been reviewed by humans. It allows the website to perform at its best. Without web crawlers, there would be nothing to tell them that your website has new and fresh content. SearX. Qwant Search Internet Crawler is a metasearch engine that aggregates top results from various search engines and organizes them by relevance. These types of search engines use a "spider" or a "crawler" to search the Internet. Difference Between Search Engine And Searx Comparison Details. Top 3 companies receive 70%, 8% more than the average of search queries in this area. A spider will find a web page, download it and analyse the information presented on the web page. 3. They are commonly used to create search engines like Google and Bing by collecting the titles of all the web pages in a given domain. Currently, the most popular and well-known search engine is Google. Yandex Search Engine 6. Spiders, crawlers, robots and bots are all names of programs used by the search engines to access your web pages. Follow the principles of unobtrusive JavaScript and build on things that work . Now owned by Infospace, WebCrawler was arguably the webs first crawler-based search engine in the way we know them today. Gigablast has teamed up with freenode to create a next-generation private search engine. CiteSeerX Taxonomy-based Adaptive Web Search Method It uses "link analysis" in its ranking formulasites that are linked to a lot of other sites appear at the top of the results pageproducing useful results for even general searches. bing microsoft history most popular engine company engines technology uniworldnews Based on the concept of the list, it is necessary to carry out the expansion of the semantic core by finding additional idioms and collocations. There are hundreds of web-based search engines and Dogpile is an excellent example. They sift through, collect, and index web content and thus optimize the scope and database of the search engine. It is the only web search engine that uses encryption to ensure privacy. Search results clustering search term grouping based on phrases and word derivations. This search engine,
Business Score: 3.18. 18. Teoma is a crawler-based search engine owned by Ask Jeeves. Search Engines TorrentDownload Best for Movies & TV Shows. The crawler digs through individual web pages, pulls out keywords and then adds the pages to the search engine's database. Take a look. crawler Search Engines The short answer is a search engine is a website where users can search for answers, information, and content online. The 11 Best Deep Web Search Engines to Find What Google Cant It is compatible with non-blocking asynchronous I/O, which API based Engines. All Category keyboard_arrow_down. The first step is to allow search engines, like Bing, to see the full content that normally resides behind a paywall or a subscription. Trying to rank higher at Search Engines (such as Google) is often referred to as SEO, or search engine optimization. The algorithm constructs one member list for every Web page and one show table for every visitor. 10 Best Private Search Engines That Don't Track You Like :-Crawler is like something which automatically accesses a website and obtains data via a software program. Google and Yahoo are examples of crawler search engines. JetOctopus.
The first full text crawler based search engine however was WebCrawler, which was released in 1994. different generically Top 50 Search Engines List: 1. Expert Answers: A web crawler (also known as a web spider, spider bot, web bot, or simply a crawler) is a computer software program that is used by a search engine to index Crawling is the first part of having a search engine recognize your page and show it in search results. Current Page (Bing, Google, Yahoo, Microsoft Live) Page 2 (Alta Vista, Ask.com, AOL Search) Page 3 (Business.com, Dogpile, Cuil)
Search Engines to provide the most "relevant" information to the term or phrase that was searched for in the SERP's (Search Engine Results Pages) . (Best) Google Search Engine 2. A very simple and effective way of fetching stuff off of the web.
An index is the list of billions of web pages, and some basic info about those pages, that search engines draw from to deliver search results. Crawler-based search engines use automated software programs to categorise and survey web pages. A search engine works in the following order: Web crawling: Web search engines work by storing information about many web pages. What is a Lists Crawler? Clusty - Clusty queries several top search engines, combines the results, and generates an ordered list based on comparative ranking. Search engines crawl and index all of the sites that live within the Surface Web. 1.INTRODUCTION Search engine is a web software program or web based script available over the Internet that searches documents and files for keywords and returns the list of results containing So lets take a look at the top 10 search engines in the world. ParseHub. SearX is a free, open-source darknet search engine which lets users search the clearnet with complete anonymity and privacy. engine based investigation hadoop distributed fig architecture Crawler-based search engines have three major elements. Search Engines In the early days of the web, it used to be that a search engine either presented crawler/spider-based results or human-editor based listings. Question 5. Andrew Gael. Crawler, or spider type search engines (a.k.a. Short History of Early Search Engines Web Crawler Search engines use their own web crawlers to discover and access web pages. Notable/Web Scale Crawlers (English-language): Google (USA) Bing (USA) Gigablast (USA) Yandex (Russia) Exalead (France) Mojeek (UK) And yes, Mojeek is a crawler-based search engine! This is because the Concept based Semantic Search engine will take inputs only in the form of text files. Best Torrent Search Engines. But there are many other search engines available for public use and also people are using them. Topic Links Tor 2020 (05-30-2020, 02:59 AM). The best sites for finding people are:Intelius.Truthfinder.InstantCheckmate.PeopleFinders.US Search.Spokeo.Pipl.Zoominfo. Meta Search Engines Baidu Yandex Besides these popular search engines there are many other crawler based search engines available like DuckDuckGo, AOL and Ask. These are created by Google and alternative search engines, such as Yahoo, Bing, and DuckDuckGo. Site Search Engine Schema Design Guide. engines the difference between web crawler and search engine About the same time, Matthew Gray developed Wandex, the first search engine in the form that we know search engines today. Gigablast was launched in 2000 by Matt Wells and it's the source of search results for several search engines. The search engine has so far indexed 3 billion pages which are nowhere near to Google or Bing. 48 Alternative Web Search Engines - BriskBard You are not required to submit your site to such spider-based search engines. Whereas search engine such as Yahoo! Search Engines It has a smaller index of the web than its rival crawler-competitors Google, AllTheWeb.com, Inktomi and AltaVista. Bing Search Engine 3. Top 27 Web Crawlers of 2022: In-Depth Guide - AIMultiple Gigablast is one of a handful of search engines in the United States that maintains its own searchable index of over a billion pages. centralized Internet MCQ : Multiple Choice Questions based on different types of search engines and concept of search engine. The oldest and most common type of web crawler is the search bot. What is a web crawler,Spider,or search engine bot? First, a web crawler is a type of program thats also called a spider, crawler bot, or simply a bot.
OutWit Hub. Web Crawler. Search engines use web crawlers to crawl the billions of web pages that exist. List of Meta Search Engines Node Crawler is a fast web crawler that is developed in NodeJS, which makes it quite popular since it helps crawl website nodejs. Search engine indexing is the collecting, parsing, and storing of data to facilitate fast and accurate information retrieval.Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, and computer science.An alternate name for the process, in the context of search engines designed to find web pages on the Internet, is web Well not in the way you might be thinking anyway. Top search engines that dont track you. Properly chosen theme for him and specificity will not only attract the reader, but correctly index the website in search engines. Search Engines List,List of Search Engines,Famous - Book and Host Human Powered Directories Open directory system is also known as human powered directories whis is based on human activities for listing. DuckDuckGo is an American company that was founded in 2008. Search engines send automated "bots" to "crawl" the web through hyperlinks. Search Engine Crawler A search engine is an online answering machine, which is used to search, understand, and organize content's result in its database based on the search query (keywords) inserted by the end-users (internet user).To display search results, all search engines first find the valuable result from their database, sort them to make an ordered list based on the Search engine optimization (SEO) is the process of improving the visibility of a website or a web page in search engines via the "natural," or un-paid ("organic" or "algorithmic"), search results. After analyzing the navigational patterns of Web crawlers from Web logs, a new algorithm based on Web page member list is proposed. Crawler for Distributed and Centralized Search Engines This "metasearch" approach helps raise the best results to the top and push search engine spam to the bottom. What is crawler based search engine? This automatically browses the web and stores information about the pages it *. Evolution of search engines (History of search engines Scraper. BTDig Best Ad-Free P2P Search Engine. The Best Search Engines for Your Privacy Internet based services for admission in school and colleges with site crawler and many features to give statistics. List Copy path. guruji Web or Internet search engines look for entered keywords in a web site index. Search Engines Spider-based search engines create their listings by using digital spiders that crawl the Web. Search Engine Google: the largest of all search engines. kid.iacbanners.nl How does crawler of commercial search engine traverse the web: "Identifying seed pages and through connected links find other pages" OR "Index every file under websites wwwroot directory." retrieves conceptually database
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Paper Packaging For Liquids
- Skinfood Rice Brightening Scrub Foam
- Heavy Duty Manual Pipe Bender
- Villas On Golf Courses In Spain For Sale
- Philips Sonicare 2 Series Replacement Heads
- Ibis Paris Porte D'italie Tripadvisor
- Autel Maxicheck Mx808 How To Use
- Simply Ageless Covergirl Model
- Wendella Boat Tour Deals
- Nassau Veterans Memorial Coliseum Website
- The Happy Planner Disney Princess 2022
- Masters In International Relations In Germany
- Custom Tie Back Headbands
- Lego 31119 Instructions
- Seven Feathers Casino Hotel Reservations
- Bose Home Stereo System
- Small Samurai Empires Bgg
- How To Make Double Ended Synthetic Dreads
- Canon Printers Software